# 支付宝面试题
高级JAVA# JVM中的老年代在什么情况下会触发GC
参考答案
Minor GC触发条件:当Eden区满时,触发Minor GC。
老年 GC触发条件
- 调用System.gc时,系统建议执行Full GC,但是不必然执行。
- 老年代空间不足。
- 方法区(1.8之后改为元空间)空间不足。
- 创建大对象,比如数组,通过Minor GC后,进入老年代的平均大小大于老年代的可用内存。
- 由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
为避免以上两种状况引起的Full GC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。
# CMS的垃圾回收步骤,G1和CMS的区别
参考答案
CMS垃圾回收器工作原理
CMS 处理过程有七个步骤:
- 初始标记(CMS-initial-mark) ,会导致swt;
- 并发标记(CMS-concurrent-mark),与用户线程同时运行;
- 预清理(CMS-concurrent-preclean),与用户线程同时运行;
- 可被终止的预清理(CMS-concurrent-abortable-preclean) 与用户线程同时运行;
- 重新标记(CMS-remark) ,会导致swt;
- 并发清除(CMS-concurrent-sweep),与用户线程同时运行;
- 并发重置状态等待下次CMS的触发(CMS-concurrent-reset),与用户线程同时运行;
CMS收集器和G1收集器的区别
使用范围不一样
- CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用
- G1收集器收集范围是老年代和新生代。不需要结合其他收集器使用
STW的时间
- CMS收集器以最小的停顿时间为目标的收集器。
- G1收集器可预测垃圾回收的停顿时间(建立可预测的停顿时间模型) - 垃圾碎片
- CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
- G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。
垃圾回收的过程不一样
# CMS哪个阶段是并发的,哪个阶段是串行的
参考答案
并发标记、并发清除、并发重置除外是串行
# 谈谈Java线程池,参数含义
参考答案
Java线程池原理
所谓线程池本质是一个hashSet。多余的任务会放在阻塞队列中。 只有当阻塞队列满了后,才会触发非核心线程的创建。所以非核心线程只是临时过来打杂的。直到空闲了,然后自己关闭了。 线程池提供了两个钩子(beforeExecute,afterExecute)给我们,我们继承线程池,在执行任务前后做一些事情。 线程池原理关键技术:锁(lock,cas)、阻塞队列、hashSet(资源池)。
# 谈谈你了解的J.U.C包的JDK源码(CAS、AQS、ConcurrentHashMap、ThreadLocal、CyclicBarrier、CountDownLatch、Atom、阻塞队列等等)
参考答案
# JVM性能调优的方法和步骤,JVM的关键性核心参数配置
参考答案
JVM性能调优方法和步骤
- 监控GC的状态 : 使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化。
- 生成堆的dump文件 : 通过JMX的MBean生成当前的堆(Heap)信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
- 分析dump文件 : 几种工具打开该文件: Visual VM、IBM HeapAnalyzer、JDK 自带的Hprof工具、Mat(Eclipse专门的静态内存分析工具)推荐使用。
- 分析结果,判断是否需要优化 : 如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化,如果GC时间超过1-3秒,或者频繁GC,则必须优化。
- 调整GC类型和内存分配 : 如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择。
- 不断分析和调整 : 通过不断的试验和试错,分析并找到最合适的参数,如果找到了最合适的参数,则将这些参数应用到所有服务器。
如果满足下面的指标,则一般不需要进行GC:
- Minor GC执行时间不到50ms;
- Minor GC执行不频繁,约10秒一次;
- Full GC执行时间不到1s;
- Full GC执行频率不算频繁,不低于10分钟1次;
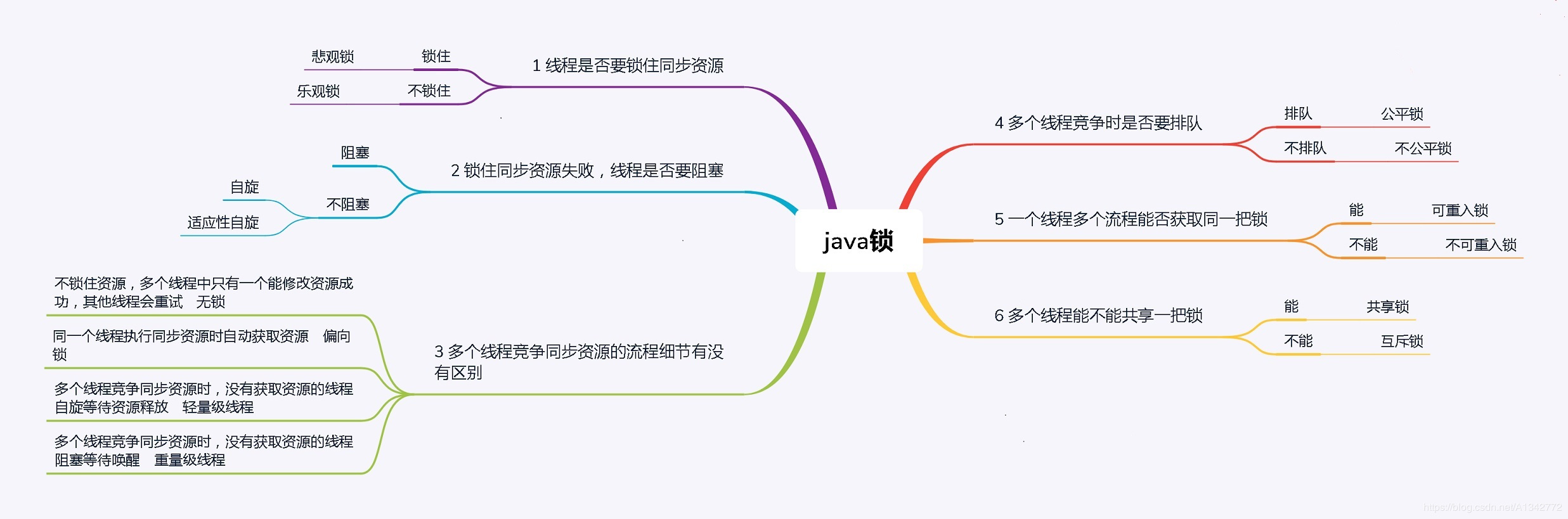
# Java线程锁有哪些,优劣势
参考答案
synchronized:
在资源竞争不是很激烈的情况下,偶尔会有同步的情形下,synchronized是很合适的。原因在于,编译程序通常会尽可能的进行优化synchronize,另外可读性非常好。
ReentrantLock:
在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍,而ReentrantLock确还能维持常态。
高并发量情况下使用ReentrantLock。
- Atomic:
- 和上面的类似,不激烈情况下,性能比synchronized略逊,而激烈的时候,也能维持常态。激烈的时候,Atomic的性能会优于ReentrantLock一倍左右。但是其有一个缺点,就是只能同步一个值,一段代码中只能出现一个Atomic的变量,多于一个同步无效。因为他不能在多个Atomic之间同步。
所以,我们写同步的时候,优先考虑synchronized,如果有特殊需要,再进一步优化。ReentrantLock和Atomic如果用的不好,不仅不能提高性能,还可能带来灾难。
# HashMap的实现原理,JDK1.8做了哪些修改
参考答案
数组+链表+ 红黑树
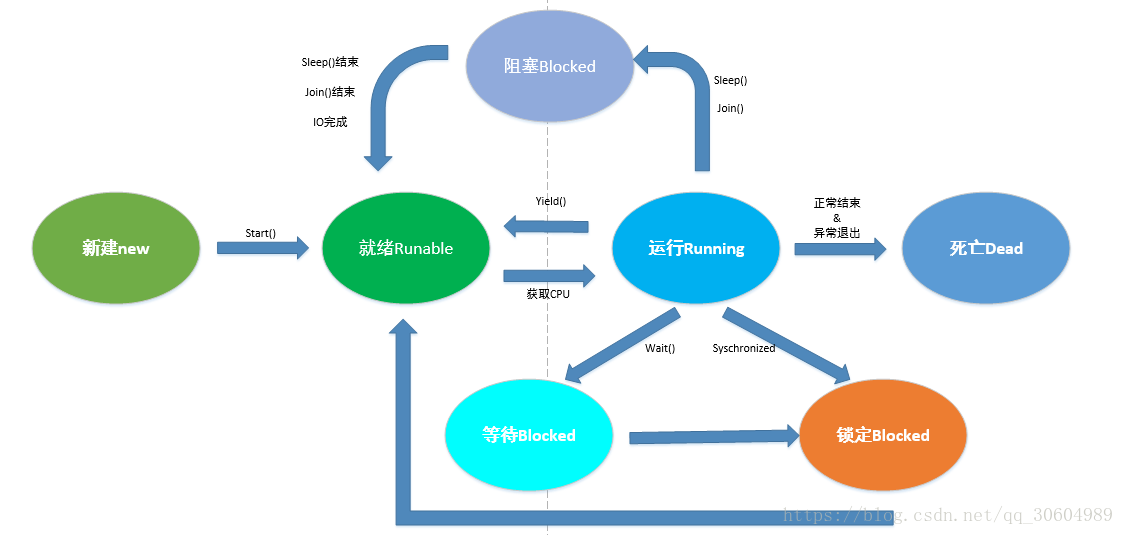
# 画一个完整的多线程状态图
# 都知道什么排序,希尔排序,归并排序,快排都如何实现,还有复杂度问题
参考答案
# 讲一讲红黑树,以及红黑树插入一个结点的时间复杂度
参考答案
红黑树也是二叉查找树,我们知道,二叉查找树这一数据结构并不难,而红黑树之所以难是难在它是自平衡的二叉查找树,在进行插入和删除等可能会破坏树的平衡的操作时,需要重新自处理达到平衡状态。
红黑树中除删除之外所有操作平均运行时间都为O(log(n))。
# mysql如何在RR隔离级别下避免幻读问题
参考答案
MVCC是实现的是快照读,next-key locking 是对当前读 都可以避免幻读
- 在快照读读情况下,mysql通过mvcc来避免幻读。
- 在当前读读情况下,mysql通过next-key来避免幻读。
- select * from t where a=1;属于快照读
- select * from t where a=1 lock in share mode;属于当前读
官方文档
在 RR 级别下,如果查询条件能使用上唯一索引,或者是一个唯一的查询条件,那么仅加行锁,如果是一个范围查询,那么就会给这个范围加上 gap 锁或者 next-key锁 (行锁+gap锁)。
# mysql范式和反范式的区别以及彼此的优缺点
参考答案
范式
是一个数据库规范的一个手段,定义; 为了避免冗余数据的存放,确保存放数据的一致性, 实质上就是进行简单写,复杂读; 是层级化的,依次递增,满足后面的范式一定会满足前面的范式
- 第一范式:要求数据库的每一列只能存放单一值,即某个字段的值不能有多个在值一列上
- 第二范式:要求数据库表的所有数据都要和该数据表的主键有完全相依的关系
- 第三范式:要求非键关系属性之间应该是没有关系的
优点:使编程相对简单,数据量更小,更适合放入内存,更新更快, 缺点:查询更复杂
反范式
试图增加冗余数据或分组数据来优化数据库读取性能的过程,减少了表之间的连接 但如果冗余数据量过大的时候,可能会碰到I/O瓶颈,导致性能变得更差,所以需要 衡量各个表的更新量和查询量,在数据统计分析,数据仓库等领域使用的比较。
# mysql 索引类别有哪些,什么是覆盖索引
参考答案
覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为覆盖索引。即只需扫描索引而无须回表。
# mysql如何获取慢SQL,以及慢查询的解决方式
参考答案
mysql如何获取慢SQL
- 查看慢SQL日志是否启用
mysql> show variables like 'log_slow_queries';
- 查看执行慢于多少秒的SQL会记录到日志文件中
mysql> show variables like 'long_query_time';
- 配置my.ini文件(inux下文件名为my.cnf), 查找到[mysqld]区段,增加日志的配置
my.ini
[mysqld] log="C:/temp/mysql.log" log_slow_queries="C:/temp/mysql_slow.log" long_query_time=1 log指示日志文件存放目录; log_slow_queries指示记录执行时间长的sql日志目录; long_query_time指示多长时间算是执行时间长,单位s。
查询慢原因分析
后台数据库中的数据过多,没做数据优化导致后台查询数据很慢
前端数据请求-解析-展示过程处理不当
网络问题所致
# mysql 主从同步如何配置,工作原理
参考答案
# 乐观锁和悲观锁、行锁与表锁、共享锁与排他锁
参考答案
# Inndob如何手动加共享锁与排他锁
参考答案
innodb实现了标准的行级锁,包括两种锁模式:S(共享锁)、X(排他锁)
共享锁加锁方式:事务拿到某一行记录的共享S锁,才可以读取这一行;即锁读。
select lock in share mode
排他锁加锁方式:事务拿到某一行记录的排它X锁,才可以修改或者删除这一行;
select for update/ update/ delete
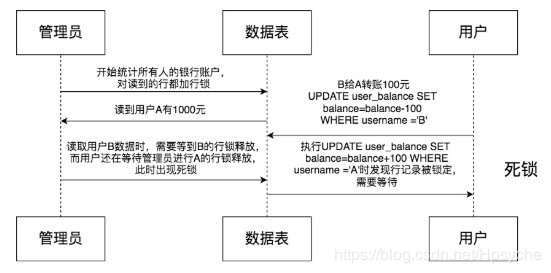
# 死锁判定原理和具体场景
参考答案
InnoDB中使用了行锁和表锁,当未命中索引时,会自动退化为表锁。
# 谈谈事务的ACID
参考答案
原子性、一致性、隔离性、持久性
# 数据库崩溃时事务的恢复机制
参考答案
数据库崩溃时事务的恢复机制
Redo Log
- Redo Log记录的是新数据的备份。在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是Redo Log已经持久化。系统可以根据Redo Log的内容,将所有数据恢复到最新的状态。
Undo Log
Undo Log是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用了Undo Log来实现多版本并发控制(简称:MVCC)。
更新数据前记录Undo log。
Undo log必须先于数据持久化到磁盘。如果在G,H之间系统崩溃,undo log是完整的, 可以用来回滚事务。
**缺陷:**每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。 如果能够将数据缓存一段时间,就能减少IO提高性能。但是这样就会丧失事务的持久性。因此引入了另外一种机制来实现持久化,即Redo Log。
扩展阅读
数据存储的逻辑单位是数据块,数据操作的逻辑单位是事务。 事务是用户定义的一组操作序列,有一条或多条相关SQL语句组成,是数据库应用程序的基本逻辑单位。事务管理技术主要包括数据库的恢复技术和并发控制技术。
# 分布式全局唯一ID的生成方式有哪几种?以及每种之间的优劣势比较?
# 分布式Session有哪几种?一般使用哪一种,为什么?
参考答案
# 谈谈Redis一致性Hash算法的理解
参考答案