# 技术栈 名词解析
# DevOps
概念解析
DevOps(Development和Operations的组合词)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。
DevOps是为了填补开发端和运维端之间的信息鸿沟,改善团队之间的协作关系。不过需要澄清的一点是,从开发到运维,中间还有测试环节。DevOps其实包含了三个部分:开发、测试和运维。
它是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
它的出现是由于软件行业日益清晰地认识到:为了按时交付软件产品和服务,开发和运营工作必须紧密合作。
扩展阅读
实现DevOps需要什么
工具上的准备:
代码管理(SCM):GitHub、GitLab、BitBucket、SubVersion
构建工具:Ant、Gradle、maven
自动部署:Capistrano、CodeDeploy
持续集成(CI):Bamboo、Hudson、Jenkins
配置管理:Ansible、Chef、Puppet、SaltStack、ScriptRock GuardRail
容器:Docker、LXC、第三方厂商如AWS
编排:Kubernetes、Core、Apache Mesos、DC/OS
服务注册与发现:Zookeeper、etcd、Consul
脚本语言:python、ruby、shell
日志管理:ELK、Logentries
系统监控:Datadog、Graphite、Icinga、Nagios zabbix
性能监控:AppDynamics、New Relic、Splunk
压力测试:JMeter、Blaze Meter、loader.io
预警:PagerDuty、pingdom、厂商自带如AWS SNS
HTTP加速器:Varnish
消息总线:ActiveMQ、SQS
应用服务器:Tomcat、JBoss
Web服务器:Apache、Nginx、IIS
数据库:MySQL、Oracle、PostgreSQL等关系型数据库;cassandra、mongoDB、redis等NoSQL数据库
项目管理(PM):Jira、Asana、Taiga、Trello、Basecamp、Pivotal Tracker
# 中台技术
概念解析
「技术中台」,说白了就是强调资源整合、能力沉淀的平台体系,当「技术前台」实现业务功能时,为他们提供底层的技术、数据等资源和能力的支持。
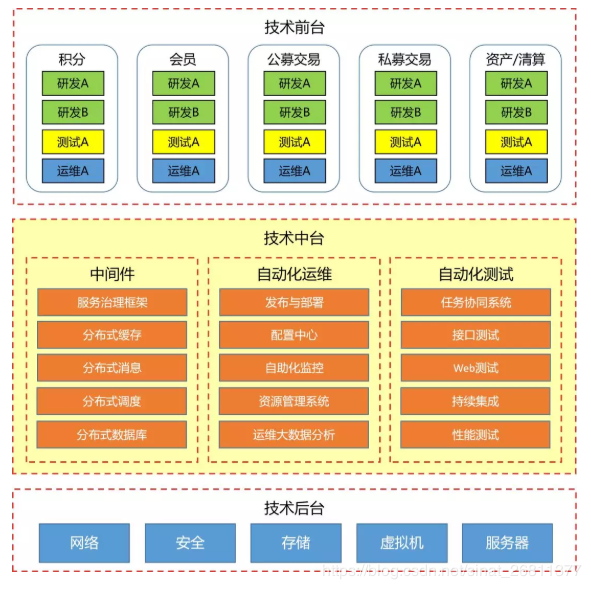
上图可见,「技术中台」有点像编程时的适配层,起到承上启下的作用,将整个公司的技术能力与业务能力分离,并以产品化方式向前台提供技术赋能,形成强力支撑。
扩展阅读
技术中台选型的前提
- 技术组织结构垂直化:也就是说,打造「技术中台」的前提是平台化,而平台化的先决条件是「组织结构垂直化,技术工具公共化」。
- 业务线多、且复杂:将可以复用的服务和代码,交由这几个组开发出服务来,给业务组使用,这样数据模型会统一,业务开发的时候,首先先看看有哪些现成的服务可以使用,不用全部从零开发,也会提高开发效率。
# 云平台
概念解析
# SAAS
软件即服务
SaaS是Software-as-a-service(软件即服务)的简称,是随着互联网技术的发展和应用软件的成熟,而在21世纪开始兴起的一种完全创新的软件应用模式。它与“on-demand software”(按需软件),the application service provider(ASP,应用服务提供商),hosted software(托管软件)所具有相似的含义。它是一种通过Internet提供软件的模式,厂商将应用软件统一部署在自己的服务器上,客户可以根据自己实际需求,通过互联网向厂商定购所需的应用软件服务,按定购的服务多少和时间长短向厂商支付费用,并通过互联网获得厂商提供的服务。用户不用再购买软件,而改用向提供商租用基于Web的软件,来管理企业经营活动,且无需对软件进行维护,服务提供商会全权管理和维护软件,软件厂商在向客户提供互联网应用的同时,也提供软件的离线操作和本地数据存储,让用户随时随地都可以使用其定购的软件和服务。对于许多小型企业来说,SaaS是采用先进技术的最好途径,它消除了企业购买、构建和维护基础设施和应用程序的需要。
# PaaS
平台即服务
Platform-as-a-Service(平台即服务)提供给消费者的服务是把客户采用提供的开发语言和工具(例如Java,python, .Net等)开发的或收购的应用程序部署到供应商的云计算基础设施上去。
客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存储等,但客户能控制部署的应用程序,也可能控制运行应用程序的托管环境配置;
# IaaS
基础设施即服务
Infrastructure-as-a-Service(基础设施即服务)提供给消费者的服务是对所有计算基础设施的利用,包括处理CPU、内存、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。
消费者不管理或控制任何云计算基础设施,但能控制操作系统的选择、存储空间、部署的应用,也有可能获得有限制的网络组件(例如路由器、,防火墙,、负载均衡器等)的控制。
扩展阅读
IaaS, PaaS和SaaS三种云计算服务模式的区别
SaaS 是软件的开发、管理、部署都交给第三方,不需要关心技术问题,可以拿来即用。普通用户接触到的互联网服务,几乎都是 SaaS,下面是一些例子。
客户管理服务 Salesforce
团队协同服务 Google Apps
储存服务 Box
储存服务 Dropbox
社交服务 Facebook / Twitter / Instagram
PaaS 提供软件部署平台(runtime),抽象掉了硬件和操作系统细节,可以无缝地扩展(scaling)。开发者只需要关注自己的业务逻辑,不需要关注底层。下面这些都属于 PaaS。
Heroku
Google App Engine
OpenShift
IaaS 是云服务的最底层,主要提供一些基础资源。它与 PaaS 的区别是,用户需要自己控制底层,实现基础设施的使用逻辑。下面这些都属于 IaaS。
Amazon EC2
Digital Ocean
RackSpace Cloud
# SPI
概念解析
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
这一机制为很多框架扩展提供了可能,比如在Dubbo、JDBC中都使用到了SPI机制。
# Hikari
概念解析
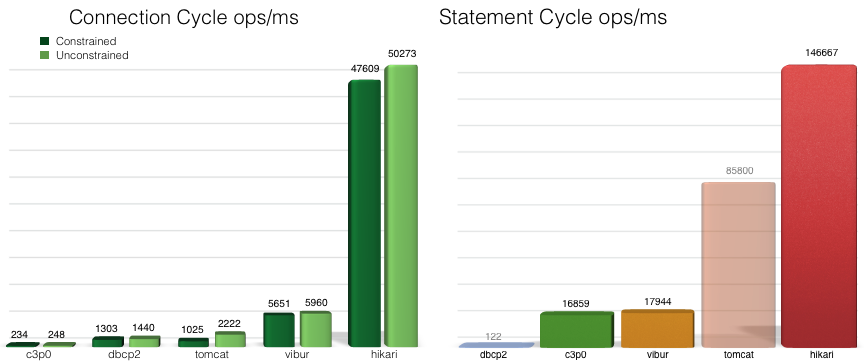
Hikari 取自日文(ひかり[shi ka li],光),是快速,简单,可靠的数据源,spring boot2.0已经将HikariCP做为切换的数据源链接池,在官网测试中秒杀一切其他数据源,例如commons-dbcp,tomcat,c3po,德鲁伊。
GitHub地址: https://github.com/brettwooldridge/HikariCP
Hikari的吞吐量性能对比图:
# 优化
- 字节码精简:优化代码,直到编译后的字节码最少,这样CPU缓存可以加载更多程序代码。
- 优化代理和拦截器:减少代码,如Hikari的Statement proxy只有100行代码,只有BoneCP的十分之一。
- 自定义数组类型(FastList):替代了ArrayList,避免每次get()都要进行 rang check,避免调用remove()时从头到尾的扫描。
- 自定义集合类型(ConcurrentBag):提高并发读写的效率。
# 基本设计
Hikari链接池采用了很多优化来提高并发数,具体可参考HikariCP WiKi 所有数据库链接池都遵守基本的设计规则,实现javax.sql.DataSource接口,里面最重要的方法就是Connection getConnection()抛出SQLException。用于获取一个Connection,一个Connection就是一个数据库链接,就是一个TCP链接,建立TCP链接是需要进行3次握手的,这降低来链接的使用效率,也是各种数据库链接池存在的原因。数据库链接池通过预先建立好Connection并缓存起来,这样的应用需要做数据查询的时候,直接从缓存中拿到Connection就可以使用来。数据库链接池还能够检测异常的链接,释放闲置的链接。
# 可靠性
对于数据库连接中断的情况,通过测试getConnection(),各种CP实现处理方法如下:
- Hikari(A级): 等待5秒钟,如果连接还是没有恢复,则抛出SQLException;后续的getConnection()处理一样。
- C3P0(C级):完全没有玩应,也没有提示,也不会在返回一个ConnectionTimout配置的超时时间后给与调用者任何通知;然后等待2分钟后醒来,返回一个error。
- Tomcat(F级):返回一个Connection ,然后调用者用这个无效的Connection执行SQL,大约55秒之后醒来,这时候getConnection()返回一个error(没有等待参数配置的5秒钟,直接返回error)。
- BoneCP(C级):跟Tomcat的处理方法一样,但是有了正常的反应,会等待5秒钟之后返回error。
# 基本字段
PoolEntryCreator POOL_ENTRY_CREATOR:用于创建PoolEntry,也就是用于创建Connection了,创建Connection是委托给驱动程序的。
Collection <Runnable> addConnectionQueue:就是一个LinkedBlockingQueue,不过不能修改其中的内容。当正在创建连接Connection的时候这个队列有值。用户逐步判断当前线程池里面是否仍需要创建新的链接。ThreadPoolExecutor addConnectionExecutor:创建Connection链接的执行是有这个线程池调度的。使用新的链接池不会而不使用当前的工作线程,以便不影响工作线程的执行(这样会导致工作线程超时)。
ThreadPoolExecutor closeConnectionExecutor:关闭Connection的链接是有这个线程池调度的。
ConcurrentBag <PoolEntry> connectionBag:这个是最重要的,一旦获取Connection都是从这里面获取,采用了ThreadLocal来减少竞争。ProxyLeakTaskFactory(泄漏任务工厂);参考ProxyLeakTask用于检测连接泄漏。
ScheduledFuture <?> houseKeeper:用于管理链接池内部的链接,链接不足的了要创建链接,链接最大生存时间到了要关闭链接。线程池中的Connection就是有它初始化的。
# HikariDataSource
Hikari中提供的DataSource是HikariDataSource,HikariDataSource实现了HikariConfig,和数据库的各种参数超时时间配置就正HikariaConfig中。提供两种初始化方式,一种是替代的构造函数,一个新
HikariDataSource时,数据源的链接不会建立,需要等到第一次调用HikariDataSource的getConnection方法。数据源建立后的相关信息保存在HikariDataSource中变量HikariPool。另一种建立方式是调用带有
HikariConfig的构造函数,这种方式适合多个数据源的建立,共享相同的部分配置。这种方式在调用构造函数的时候就建立了数据源的链接。HikariDataSource的所有数据源获取都委托给了HikariPool,一个数据源会有一个HikariPool,一个HikariPool中有一个ConcurrentBag,一个ConcurrentBag中多个PoolEntry,一个PoolEntry对应一个Connection。
# FastList
一个重要的(性能方面的)优化是消除了在ConnectionProxy中使用ArrayList实例来跟踪打开的语句实例。当一个语句被关闭时,它必须从这个集合中删除,当连接被关闭时,它必须迭代这个集合并关闭任何打开的语句实例,最后必须清除这个集合。Java ArrayList在每次get(int索引)调用时执行范围检查,这对于一般用途来说是明智的。但是,因为我们可以提供关于范围的保证,所以这种检查只是开销。
此外,remove(对象)实现从头到尾执行扫描,但是JDBC编程中的常见模式是在使用语句后立即关闭语句,或者以相反的顺序打开语句。在这种情况下,从尾部开始的扫描会有更好的效果。因此,ArrayList<sql>被替换为一个自定义类FastList,它消除了范围检查,并执行从尾部到头部的删除扫描。
# ConcurrentBag
ConcurrentBag(并发袋)设计主要为了解决并发对资源的争用,其中主要有CopyOnWriteArrayList <T> sharedList和ThreadLocal <List <Object >> threadList,SynchronousQueue <T> handoffQueue,当一个线程获取链接的时候首先从自己的ThreadLocal中的threadList获取,当获取失败的时候才从sharedList获取,当从sharedList获取还是失败的话,就等待在handoffQueue,这是一个同步的队列,当其他线程释放链接的时候,自己就会被唤醒。
无锁的设计
ThreadLocal缓存
Queue-stealing
直接传球给队友的优化
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 从threadList获取链接
final List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 从sharedList获取链接
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// If we may have stolen another waiter's connection, request another bag add.
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
//等待其他线程释放链接,超过timeout就获取失败了
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
# Hikari在Maven中的依赖
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.1</version>
</dependency>
# Hikari在yml中的配置
# 数据库配置
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/ssm?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: root
# Hikari 连接池配置
# 最小空闲连接数量
hikari:
minimum-idle: 5
# 空闲连接存活最大时间,默认600000(10分钟)
idle-timeout: 180000
# 连接池最大连接数,默认是10
maximum-pool-size: 10
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
# 连接池名称
pool-name: MyHikariCP
# 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒,即30000
connection-timeout: 30000
connection-test-query: SELECT 1
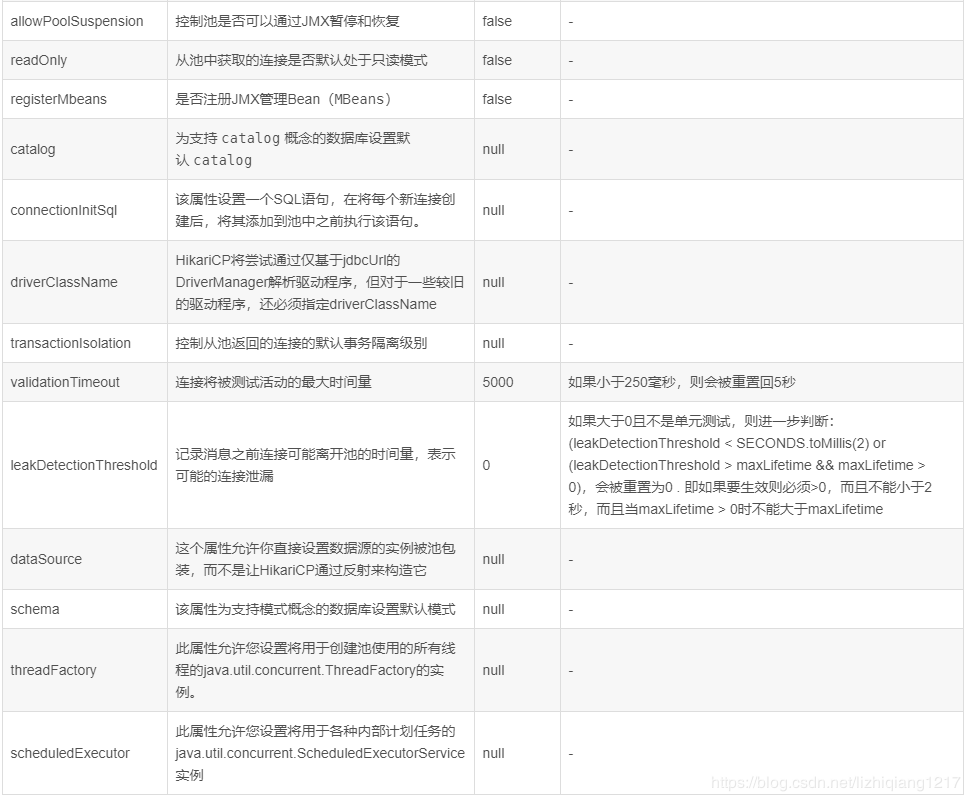
# Hikari配置参数

# 埋点
埋点
埋点的概念
- 数据埋点是数据采集的一种重要方式,主要用来记录和收集终端用户的操作行为,其基本原理是在App/H5/PC等终端部署采集的SDK代码,当用户的行为满足某种条件的时候,比如进入某个页面、点击某个按钮等,会自动触发记录和存储,然后这些数据会被收集并被传输到终端提供商,或者是通过后端采集用户使用服务过程中的请求数据。
埋点的用途
- 终端提供商在收集到埋点数据之后,通过大数据处理、数据统计、数据分析、数据挖掘等加工处理,可以得到衡量产品状态的一些基本指标,比如活跃、留存、新增等大盘数据,从而洞察产品的状态。此外更重要的是随着数据挖掘等技术的兴起,埋点采集到的数据在以下方面的作用也越来越凸显:
- 驱动决策:ABtest、漏斗优化、用户增长、bug修复、精准营销、流失用户预警
- 驱动产品智能:智能推荐(千人千面)、场景化提示(私人助理)等
- 驱动安全:风险识别
# DDD
领域驱动设计
DDD(Domain-Driven Design 领域驱动设计)是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建模,以应对系统规模过大时引起的软件复杂性的问题。整个过程大概是这样的,开发团队和领域专家一起通过 通用语言(Ubiquitous Language)去理解和消化领域知识,从领域知识中提取和划分为一个一个的子领域(核心子域,通用子域,支撑子域),并在子领域上建立模型,再重复以上步骤,这样周而复始,构建出一套符合当前领域的模型。
# PDD
产品特性驱动设计
PDD(Product-Feature Driven Design)产品特性驱动设计,我们可以将它使用在我们的日常设计工作中,它可以运用在你的大小设计项目中,这是一种行为模式,一种思考角度,或者我们把它作为一种指导方法.它依靠产品的自身特性来驱动设计.它的成效非常明显,缩短了项目的时间,优化了项目流程,在项目中起到了设计的主动与严谨性,为我们的成果产生了直接的正面影响,并起到了强有力的支撑效应。
# UGC
用户生成内容
互联网术语,全称为User Generated Content,也就是用户生成内容的意思。UGC的概念最早起源于互联网领域,即用户将自己原创的内容通过互联网平台进行展示或者提供给其他用户。UGC是伴随着以提倡个性化为主要特点的Web2.0概念兴起的。
# Mesos
概述
Apache Mesos是一款基于多资源(内存、CPU、磁盘、端口等)调度的开源集群管理套件,能使容错和分布式系统更加容易使用。其采用了Master/Slave结构来简化设计,将Master做的尽可能轻量级,仅保存了各种计算框架(Framwork)和Mesos Slave的状态信息,这些状态很容易在Mesos出现故障时被重构,所以使用zookeeper解决master单点故障问题。
# Mesos工作原理
工作原理
Mesos Master充当全局资源调度器角色,采用某种策略算法将某个Save 上的空闲资源分配给某个Famework,而各种Framework则是通过自己的调度器向master注册进行接入,master slave则是收集任务状态和启动各个Framework的Executor。
- Mesos master:负责管理各个Framework和Slave,并将Slave 上的资源分配给各个Framework。
- Mesos Slave:负责管理本节点上的各个Mesos Task,为各个Executor分配资源。
- Framework:计算框架,如:Hadoop、Spark等,可以通过MesosSchedulerDiver接入Mesos。
- Executor:执行器,在Mesos Slave上安装,用于启动计算框架中的Task。
# package-info.java
概述
pacakge-info.java是一个Java文件,可以添加到任何的Java源码包中。pacakge-info.java的目标是提供一个包级的文档说明或者是包级的注释。pacakge-info.java文件中,唯一要求包含的内容是包的声明语句。Spring源码中,每个包中就会有一个package-info.java的类,也意味着一种规范。有如下特点:
- 不能随便被创建,由于包含
-非法字符,无法通过IDE工具来创建,但是可以拷贝复制到包下; - 不能有实现代码,
package-info.java也会被编译成package-info.class,但是在package-info.java文件里不能声明package-info的类名称。 - 用于
JavaDoc的生成,比如:
/**
* xxx包描述<br>
* @author xxx <br>
* date: 2020.01.23
* @since 1.8
* @version 1.0.0
*
*/
package com.cn.xxx;
- 包注释:注释对于程序员来说非常重要,
pacakge-info.java文件包含了包级的注释。我们还可以使用ElementType来自定义注释。比如:在包声明上加@Deprecated注解,可以让包中的所有类、接口等均为已过时。
@Deprecated
package com.cn.xxx;